1. Introduction to Machine Learning for Beginners
Machine learning (ML) for beginners can be compared to teaching a child how to spot a ripe mango. Instead of memorizing rules like “yellow and soft means ripe,” you show many examples of ripe and unripe mangoes. Over time, the child learns patterns on their own. Machine learning works the same way: instead of hard-coding rules, we give computers data, and they learn to make predictions or decisions by finding patterns.
Machine learning is a core idea in artificial intelligence and powers many tools we use daily. From Netflix recommendations and Amazon product suggestions to fraud detection in banks and diagnostic support in hospitals, ML is now practical technology shaping industries and everyday life. Learning step by step not only helps you understand how these systems work but also prepares you to build your own projects in the future.
Before moving further, here is a quick overview of what this guide covers:
Table of Contents
What is AI, ML, and DL?
Artificial Intelligence (AI):
Artificial Intelligence is the broad field of making machines act in ways that seem intelligent. The goal of AI is to build systems that can solve problems, make decisions, and perform tasks that usually require human thinking. AI covers many areas such as understanding language, recognizing images, reasoning through logic, and even playing games.
New to AI? Start with AI Fundamentals: A Beginner’s Guide to Artificial Intelligence
A good example is ChatGPT, which can generate text, answer questions, or help with writing by understanding patterns in language. Another example is AI in modern video games, where computer opponents adapt their strategy to make gameplay more realistic.
Machine Learning (ML):
Machine Learning (ML) is a branch of AI that enables systems to learn from data instead of following fixed rules. Rather than programming every instruction, we provide examples and let the system discover patterns on its own. As ML models train on more data, they improve in accuracy, making them powerful for tasks where writing clear rules is too complex or impractical.
For example, think about email spam filters. A spam filter is trained on thousands of emails labeled as “spam” or “not spam.” Over time, the system learns which words, phrases, or patterns are likely to appear in spam messages. When a new email arrives, the machine learning model predicts whether it belongs in your inbox or spam folder. The more emails it processes, the better its predictions become.
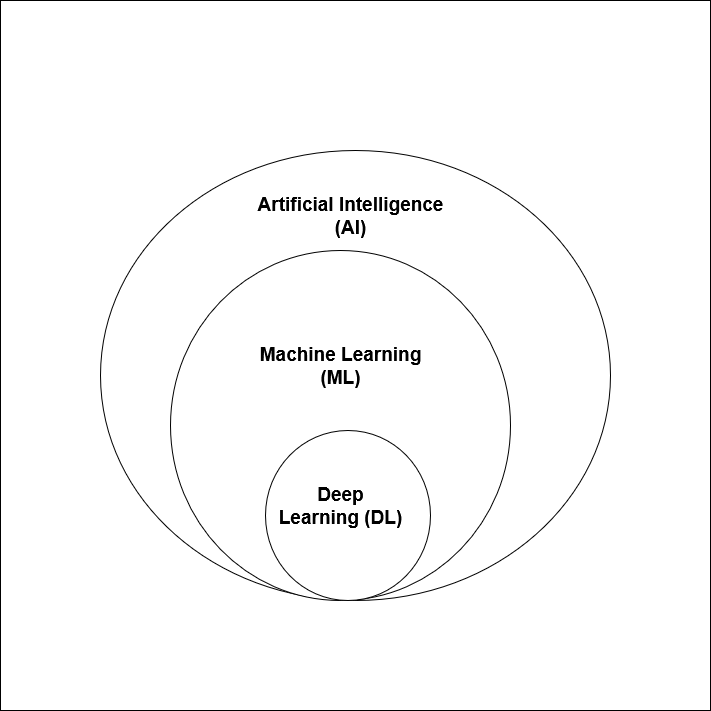
Deep Learning (DL):
Deep Learning is a specialized part of machine learning that uses structures called neural networks. These networks are made up of many layers, which is why they are called “deep.” Each layer processes information and passes it to the next, allowing the system to recognize highly complex patterns.
Deep learning is especially powerful for tasks involving images, audio, and natural language because it can capture subtle features that simpler algorithms might miss.
A real-world example is how self-driving cars work. Cameras on the car capture images of the road. A deep learning model processes those images to recognize traffic lights, pedestrians, road signs, and other vehicles. The car then decides how to act based on this information. Another example is Google Translate, which uses deep learning to translate entire sentences from one language to another by analyzing massive amounts of multilingual text.
Why Machine Learning Matters Today
Machine Learning is all around us. It powers Netflix and YouTube recommendations, helps banks detect fraud, supports doctors in diagnosing diseases, and makes tools like Google Photos or voice assistants smarter. Because businesses and individuals now generate huge amounts of data, ML has become the key technology for turning that data into useful insights.
Learning ML is also valuable for your career. Companies in technology, healthcare, finance, and many other industries look for people who understand how data-driven systems work. Even if you are not building models yourself, knowing the basics of ML helps you understand the tools shaping decisions in daily life.
Traditional Programming vs. Machine Learning
Traditional programming relies on rules written by humans. You provide the rules and data, and the computer produces an answer. For example, to calculate tax, you feed in the income (data) and the formula (rules), and the program gives the result.
Machine Learning works differently. You give the computer data and the correct answers, and it figures out the rules by itself. The system creates a model that can then predict answers for new, unseen data. A common example is a spam filter, which learns patterns of spam from many examples and then applies those learned rules to incoming emails.
2. Core Concepts in Machine Learning
Features and Labels
In machine learning, data is usually divided into two parts: features and labels. Features are the input variables that describe the problem, such as age, income, or number of website visits. The label is the target outcome that we want to predict, such as whether a customer will buy a product or whether a patient has a certain disease.
For example, if we are building a model to predict house prices, the features could include the size of the house, number of rooms, and location. The label would be the actual selling price. Features provide the clues, and the label gives the answer we want the model to learn.
Structured vs. Unstructured Data
Data comes in two main types: structured and unstructured. Structured data is neatly organized in rows and columns, such as spreadsheets or databases. It is easy to handle and commonly used in business tasks like sales forecasting or customer analysis.
Unstructured data, on the other hand, includes text, images, audio, and video. For example, social media posts, photos, or voice recordings are all unstructured. Machine learning models need more advanced techniques, like natural language processing or image recognition, to make sense of this type of data.
Data Splits: Train, Validation, and Test
To create reliable models, we divide the dataset into three parts. The training set is used to teach the model, the validation set is used to tune settings and improve accuracy, and the test set checks how well the model performs on new, unseen data. This prevents the model from only memorizing patterns.
For example, if you train a spam filter on all your emails and then test it on the same emails, it may look perfect but fail on new ones. By splitting data, you make sure the model is evaluated fairly and can generalize to fresh inputs.
Overfitting vs. Underfitting
Overfitting happens when the model learns too much from the training data, including random noise, and cannot perform well on new data. Underfitting is when the model is too simple and misses important patterns, leading to poor accuracy.
For example, if a student memorizes exact answers to past exam questions, they may fail when new questions appear. That is overfitting. If another student only skims the material and learns too little, that is underfitting. The best student studies in a balanced way and performs well in any situation, just like a good ML model.
Bias–Variance Tradeoff
The bias–variance tradeoff is about balancing simplicity and complexity in models. A high-bias model is too simple, makes strong assumptions, and often misses patterns. A high-variance model is too complex and reacts too much to small changes in the data.
Imagine trying to fit a line to a set of points. A straight line may miss many details (high bias), while a curve that passes through every single point may be too wiggly and fail on new data (high variance). The goal is to find a balance that captures the main pattern without being overly rigid or overly flexible.
Cross Validation
Cross validation is a method to test how reliable a model is. Instead of using just one split of the data, the dataset is divided into several smaller parts. The model is trained and tested multiple times on different combinations of these parts.
For example, if you split your data into five sections, the model trains on four and tests on the fifth. This process repeats until each section has been tested once. If the results are consistent across all tests, you know the model is stable and dependable.
Scaling and Normalization
When features have very different ranges, models may struggle to compare them fairly. For instance, income can be in thousands, while age is usually between 1 and 100. Without adjustments, models might give too much importance to features with larger values.
Scaling and normalization solve this by bringing values into a common range. For example, dividing all features by their maximum value can place them between 0 and 1. This makes sure the model treats each feature equally during training.
Curse of Dimensionality
As the number of features grows, it becomes harder for models to find meaningful patterns. This problem is called the curse of dimensionality. Too many features can confuse the model, make it slower, and reduce its accuracy.
For example, imagine trying to identify customer preferences with thousands of unnecessary details. Instead of helping, the extra information creates noise. To fix this, techniques like feature selection or Principal Component Analysis (PCA) reduce the data into fewer but more meaningful features.
3. Types of Machine Learning
Supervised Learning
Supervised learning means the model learns from labeled data. Every input comes with the correct answer (the label), and the system tries to discover the relationship between inputs and outputs. It is the most common and practical type of machine learning because it provides clear feedback during training.
There are two main approaches here:
1. Regression
Regression is used when the output is a continuous value. Continuous means the answer can take any number within a range, including decimals, and it changes smoothly rather than in fixed jumps. Regression problems are about predicting quantities, like height, weight, temperature, or price.
A good example is predicting house prices. Features like size, number of rooms, and location are inputs, while the selling price is the label.
2. Classification
Classification is used when the output is a discrete value. Discrete means the answer comes from a fixed set of categories, with no values in between. Classification problems are about predicting labels, such as colors, species, or categories.
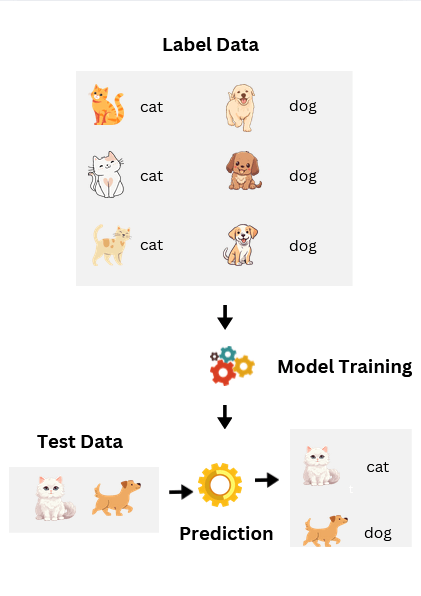
An easy case is predicting whether an image shows a cat or a dog. The features are the pixel values of the image, and the label is the animal type. The model must choose one category from the set, not something in between.
Unsupervised Learning
Unsupervised learning works with unlabeled data. The system does not know the answers in advance; it tries to find hidden patterns or groupings on its own. This makes it useful for exploring data when labels are not available.
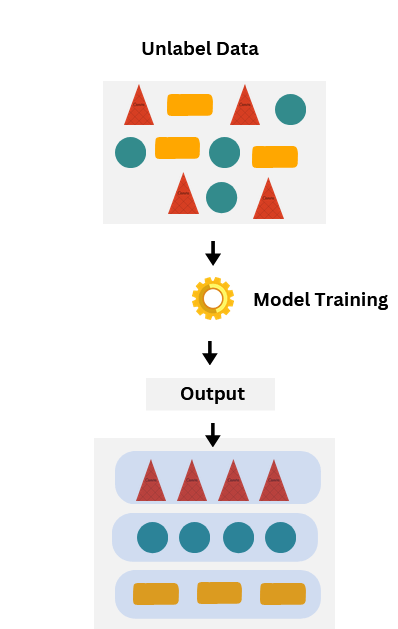
Clustering is one of the main methods. For example, businesses use clustering to group customers into segments based on purchasing behavior. Another method is dimensionality reduction, which simplifies large datasets while keeping the most important patterns.
Reinforcement Learning
In reinforcement learning, an agent learns by interacting with an environment and receiving rewards or penalties for its actions. Over time, it improves by choosing actions that maximize rewards. This approach is inspired by how humans and animals learn from trial and error.
A common example is gaming. Systems like AlphaGo learned to play complex games by playing millions of rounds against themselves. Reinforcement learning is also used in robotics for teaching machines to walk and in self-driving cars for decision-making on the road.
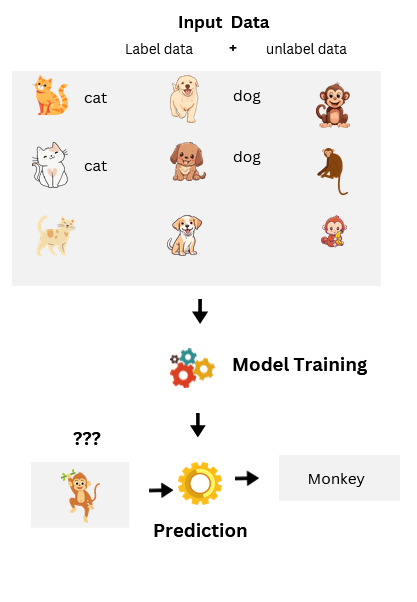
Semi-Supervised and Self-Supervised Learning
Semi-supervised learning uses a mix of labeled and unlabeled data. This is useful when labeling data is expensive or time-consuming. The model learns from a small amount of labeled data and improves further using the larger pool of unlabeled data.
Self-supervised learning has become key for modern AI. In this approach, the system creates labels from the data itself. ChatGPT, for example, is trained with self-supervised methods by predicting missing words in massive amounts of text. This allows it to learn language patterns without needing humans to label every example.
4. Machine Learning Workflow (End-to-End Pipeline)
The machine learning workflow is the step-by-step process of turning raw data into a working model that can be used in the real world. While the exact steps may vary depending on the project, most workflows include collecting data, preparing it, training models, and improving them through testing and iteration. It is not a rigid formula but a general roadmap that ensures models are built systematically and remain useful over time.
1. Collect Data
Every ML project begins with gathering data. This can come from sources like company databases, sensors, surveys, or public datasets. Without enough data, even the best algorithms cannot perform well.
For example, an e-commerce company might collect purchase histories, product details, and customer demographics to build a recommendation system.
2. Clean and Preprocess Data
Raw data is rarely perfect. It may contain missing values, errors, or inconsistencies. Preprocessing ensures that the data is accurate and ready for modeling.
For instance, filling in missing ages, removing duplicate entries, or converting categories like “Male” and “Female” into numbers are common preprocessing tasks.
3. Explore with Visualization
Exploratory Data Analysis (EDA) helps uncover patterns, distributions, and potential issues in the dataset. Visualization tools like histograms or scatter plots are used at this stage.
As an example, plotting customer ages might reveal that most buyers are between 25 and 40, which could influence feature selection or business insights.
4. Feature Engineering
Feature engineering is the process of creating or transforming input variables so they better represent the problem for the model. Good features can often improve performance more than choosing a different algorithm.
For example, instead of using raw date values, you might extract “day of the week” or “month” to capture seasonal trends. Similarly, combining “height” and “weight” into a new feature like “BMI” can give the model a more useful signal.
5. Split Train, Validation, and Test Sets
To check how well a model works, data is divided into three sets. Training data is used to teach the model, validation data tunes the model, and test data evaluates final performance.
For example, a spam filter might be trained on 70 percent of emails, tuned on 15 percent, and tested on the remaining 15 percent to ensure it works on new messages.
6. Train Baseline and Improve
A baseline model is the simplest version of a model. It sets a starting point to compare improvements against. From there, better models and techniques are applied.
For instance, predicting house prices could start with a simple linear regression baseline. Later, more advanced models like decision trees or random forests can be added for higher accuracy.
7. Evaluate with Correct Metrics
Different problems need different evaluation metrics. Accuracy works for balanced datasets, but precision, recall, or F1-score may be better for imbalanced ones like fraud detection.
For example, in medical diagnosis, recall is critical because missing a sick patient (false negative) is more dangerous than mistakenly flagging a healthy one.
8. Hyperparameter Tuning
Hyperparameters are the settings that control how a model learns, and tuning them helps find the best combination for performance. Unlike model parameters (which the model learns), hyperparameters must be set by the developer before training.
For instance, in a Random Forest model, the number of trees and the maximum depth of each tree are hyperparameters. Testing different values, often through methods like grid search or random search, can significantly improve accuracy and reliability.
9. Deploy to Real Users
Once trained and tested, the model is deployed so real users or systems can benefit from it. Deployment often means integrating the model into apps or websites.
For instance, a recommendation model could be deployed on an e-commerce website to suggest products in real time as customers shop.
10. Monitor for Drift
Over time, the world changes, and data patterns shift. This can make models less accurate, a problem called data drift. Monitoring ensures performance stays consistent.
For example, a credit scoring model trained on past customer data may fail if new economic conditions change spending behavior.
11. Iterate Continuously
Machine learning is not a one-time process. With new data and feedback, models are updated and improved in cycles. This keeps them relevant and accurate.
Think of a spam filter: as spammers change tactics, the model needs to retrain with the latest examples to stay effective.
5. Tools and Ecosystem
Machine learning is supported by a wide range of tools, but beginners don’t need to learn them all at once. Here are the essentials:
- Programming Language: Python is the most popular choice for ML, thanks to its simplicity and rich libraries. R is also used for statistics and visualization.
- Data Handling & Visualization: NumPy, Pandas, and Polars (fast alternative) are key for data processing. For visualization, Matplotlib, Seaborn, and Plotly help turn numbers into insights.
- ML & DL Libraries: Use scikit-learn for classical ML. For deep learning, start with TensorFlow/Keras or PyTorch (widely used in research and industry). For structured data, boosting libraries like XGBoost and LightGBM are very effective.
- Practice & Development: Jupyter Notebook and Google Colab make it easy to experiment. Kaggle offers free datasets and coding environments. As you advance, use IDEs like VS Code or PyCharm.
- Collaboration & Deployment: Git/GitHub for version control, MLflow or Weights & Biases for experiment tracking, and tools like Streamlit or FastAPI for turning models into apps. Cloud services (AWS SageMaker, Google Vertex AI, Azure ML) support large-scale projects.
6. Applications of Machine Learning
Recommendations
Recommendation systems are one of the most visible uses of ML. They analyze your past behavior and compare it with millions of other users to suggest content or products you are likely to enjoy.
For example, Netflix suggests movies and series based on your watch history, while Amazon recommends products you may want to buy.
Fraud Detection
Banks and financial institutions use ML to spot unusual activity in real time. Models learn patterns of normal spending and raise alerts when something looks suspicious.
For example, if your credit card is suddenly used in another country or for an unusual purchase, the system may block the transaction or ask for extra verification.
Predictive Sales and Customer Churn
Companies use ML to predict future sales and identify customers who may leave (churn). By analyzing past purchases, browsing history, and engagement, ML helps businesses take action early.
For example, a telecom company might use ML to spot which customers are at risk of canceling their plans and offer them special deals to stay.
Healthcare
ML plays an important role in diagnostics and treatment predictions. Models can analyze medical images, lab results, or patient records to support doctors in decision-making.
For instance, ML systems can detect early signs of diseases like cancer in X-rays or predict how well a patient may respond to a particular treatment.
Natural Language Processing (NLP)
NLP allows machines to understand and generate human language. Chatbots, translation tools, and voice assistants all rely on ML to process text and speech.
For example, ML powers customer service chatbots that answer questions instantly or apps like Google Translate that convert one language into another in seconds.
Computer Vision
Computer vision enables machines to interpret images and videos. It is widely used in security, manufacturing, and consumer devices.
For example, smartphones use face recognition to unlock, and factories use vision systems to detect product defects automatically.
Forecasting
ML is also used in forecasting future trends by analyzing past data. This is useful in finance, supply chains, and weather prediction.
For instance, stock prediction models look for patterns in historical prices, while supermarkets use ML to forecast demand and plan inventory.
7. Challenges in Machine Learning
Data Quality
The success of any machine learning model depends heavily on the quality of data. If the dataset is incomplete, biased, or filled with errors, the model will learn those flaws and perform poorly. In fact, preparing and cleaning data often takes more time than building the model itself.
To deal with this, teams focus on proper data preprocessing, cleaning missing values, and collecting diverse datasets. Using techniques like data augmentation or sourcing data from multiple channels can also reduce bias and improve reliability.
Model Complexity
Another challenge is choosing the right level of complexity. Sometimes simple models, like linear regression, can solve a problem effectively. However, beginners often rush to advanced algorithms without considering if they are needed. More complex models require more data, computing power, and careful tuning.
The best approach is to start with a simple baseline model, measure performance, and only move to more complex methods if needed. This helps save time, resources, and also makes the solution easier to interpret.
Interpretability
Many machine learning models, especially deep learning systems, work like a black box. This makes it difficult to explain why a certain decision was made. In areas such as healthcare or finance, where trust and accountability are critical, lack of interpretability can limit adoption of machine learning solutions.
To address this, techniques like LIME or SHAP values are used to explain model predictions. Choosing simpler, more interpretable models when possible and documenting the decision-making process also improves trust in the system.
8. Responsible and Ethical AI
Bias and Fairness
Machine learning models learn from historical data. If that data contains biases, the model can repeat or even amplify them. This is a serious concern when AI is used in hiring, lending, or law enforcement, because unfair predictions can reinforce existing inequalities.
For example, a hiring model trained mostly on resumes from men may unintentionally favor male candidates over female candidates, even if both have the same skills. Ensuring fairness requires diverse datasets and regular checks for bias.
Transparency and Explainability
Many ML models, especially deep learning systems, work like a black box, making it hard to understand how decisions are made. Transparency is about making models explainable so people can trust and verify the results.
For instance, in healthcare, doctors need to know why an AI system recommended a certain treatment. Techniques like SHAP values or LIME can help explain which features influenced the prediction.
Privacy and Data Governance
Machine learning often uses sensitive personal information such as medical records, financial details, or browsing history. Protecting this data is essential. Privacy can be maintained through anonymization, encryption, and following strict data governance rules.
For example, a hospital using ML for diagnosis must ensure that patient data is securely stored and used only with proper consent.
9. Career and Learning Path
Starting with machine learning does not require advanced math or heavy coding right away. The best entry point is learning Python, along with the basics of NumPy and Pandas for handling data. Once you are comfortable with these, move to scikit-learn to explore classical ML algorithms such as regression and classification. These tools let you experience the complete cycle of training and evaluating models.
The next step is practice. Small projects like predicting house prices, classifying emails, or analyzing datasets from Kaggle help you apply concepts in a practical way. Over time, you can explore deep learning frameworks such as TensorFlow or PyTorch for advanced tasks like image recognition and natural language processing.
To guide your journey, high-quality resources make a big difference. Focus on building projects, reading official documentation, and practicing regularly. With consistency, you’ll gain confidence and move step by step from beginner to advanced levels. For recommended books and courses, see the References section below.
10. Resources to Learn More
If you are serious about learning machine learning, the right resources will speed up your journey. Here are some recommended starting points:
Disclosure: This article Machine Learning for Beginners: A Simple Guide contains affiliate links. If you purchase through them, we may earn a small commission at no extra cost to you. This helps support Noro Insight in creating more free content for readers.
Books
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow [affiliate link] – A practical, beginner-friendly book that walks you through both classical ML and deep learning.
- The Hundred-Page Machine Learning Book [affiliate link] – A concise, high-impact read that covers the core concepts of machine learning in an accessible way.
- Machine Learning for Absolute Beginners [affiliate link] by Oliver Theobald — (very beginner-friendly) Introduces the ideas in plain English, with minimal math or prerequisites.
Courses
- AI For Everyone – A nontechnical course that teaches how AI works, how it affects businesses, and how to think about it — no coding required. Coursera
- Machine Learning A-Z: AI, Python & R – A practical Udemy course that teaches ML with Python and R, including projects and code templates.
- Google’s Machine Learning Crash Course – Hands-on lessons with code examples, exercises, and visualizations to bring theory into practice. (by Google)
- AI For Beginners (Microsoft) – A 12-week curriculum with 24 lessons, labs, and quizzes to introduce core AI & ML concepts. Microsoft GitHub
- Machine Learning Specialization – A beginner-friendly three-course program by Andrew Ng to master foundational ML concepts and practical skills. Coursera
Practice Platforms
- Kaggle – Offers free datasets, tutorials, and competitions to practice ML in real-world scenarios.
- Google Colab – Lets you run notebooks in the cloud without installing anything.
- GitHub – Explore open-source ML projects to see how others structure their work.
With these resources, you can move from beginner to intermediate level while working on projects that showcase your skills. The key is consistency: read, practice, and build small projects regularly.
11. Final Thoughts
Machine learning is no longer just a research topic, it is part of our daily lives. From streaming recommendations to fraud detection, it powers the apps and services we use every day. By learning the basics such as features, labels, workflows, and applications, you build the foundation to explore deeper areas of AI with confidence.
As you continue your journey, remember that machine learning is about solving real problems, not just applying complex algorithms. Start small, focus on data quality, and build projects that truly interest you. With steady practice and the right resources, anyone can develop strong ML skills. Just as important, learning with a responsible mindset ensures the models you create are fair, transparent, and genuinely useful for people.