1. Understanding the Fundamentals of Data
When people think about artificial intelligence(AI), they often imagine advanced algorithms and complex models. But the real foundation of AI is data. Understanding the Fundamentals of Data is essential because algorithms can only learn from the examples and patterns data provides.
New to AI? Start with AI Fundamentals: A Beginner’s Guide to Artificial Intelligence
Data is simply a collection of facts or measurements, but it becomes valuable only when it is processed in a meaningful way. When data is organized, it becomes information. When patterns appear, it becomes knowledge. And when that knowledge is used to guide decisions, it turns into wisdom that helps solve real problems.
For example, knowing that Kathmandu’s temperature is 35°C is information. Realizing it has increased by 2°C over ten years is knowledge. Using that trend to plan climate strategies shows how data transforms into practical wisdom that supports better decisions.
Before moving further, here is a quick overview of what this guide covers:
Table of Contents
Why Data Matters
Data is the foundation of every intelligent system. Algorithms alone do not create intelligence; they simply learn from data patterns. When the data is rich, accurate, and well-structured, models can recognize meaningful relationships and make reliable predictions. But when the data is poor, biased, or inconsistent, the results quickly fall apart. This is the essence of Garbage In, Garbage Out (GIGO). Poor-quality data always leads to poor-quality outcomes.
Most AI and machine learning failures happen not because of model design but because of low-quality or misunderstood data. Clean, consistent, and trustworthy data separates successful AI systems from unreliable ones. In short, data quality determines the quality of intelligence.
Quality Over Quantity
In AI, more data does not always mean better results. What truly matters is the quality of the data. Large datasets with errors or bias can weaken performance, while smaller, clean, and well-prepared data often lead to more accurate and trustworthy models. In short, high-quality data always beats high-volume data.
Data in the Machine Learning Workflow
New to Machine Learning? Start with Machine Learning for Beginners: A Simple Guide
In a typical machine learning workflow, data moves through several key stages. It starts with collection, where information is gathered from different sources. Next comes cleaning, which fixes errors, removes duplicates, and handles missing values. The transformation stage prepares the data for analysis through scaling, encoding, or reshaping. Then comes modeling, where algorithms learn from the prepared data. Finally, evaluation and monitoring ensure that models perform consistently and stay reliable over time.
2. Types of Data
Data can be viewed in different ways depending on how it is structured, measured, or collected. Understanding these categories helps in selecting the right analysis and modeling approach in AI and machine learning.
2.1 By Structure
Data can differ based on how it is organized. Some data follows a fixed format, while some is flexible or completely free-form. Understanding these structural types helps you choose the right tools, storage systems, and machine learning methods.
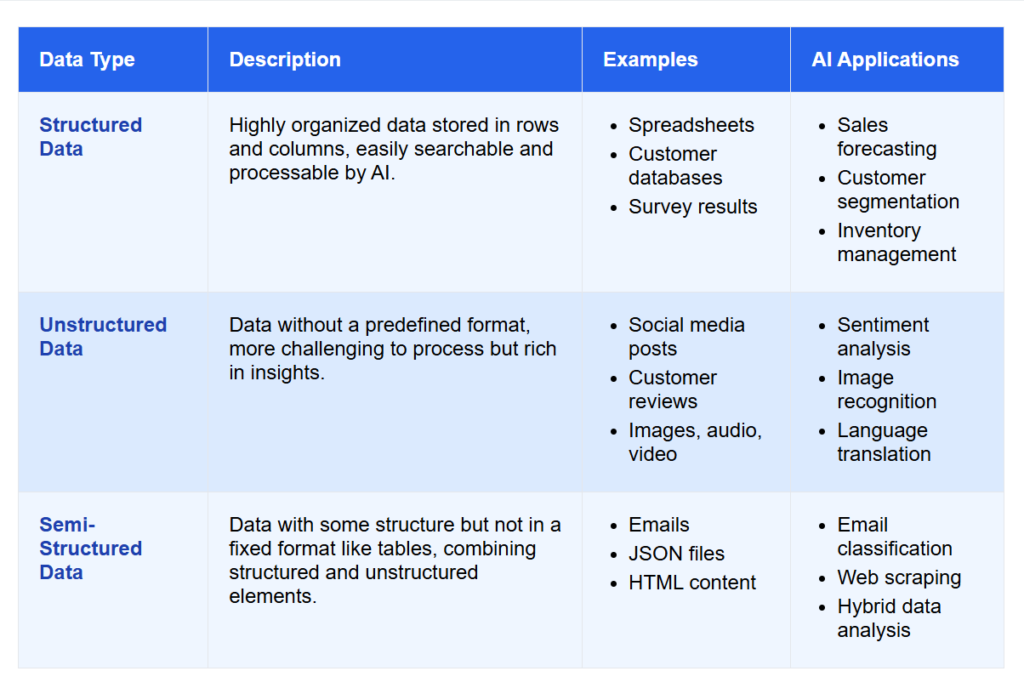
Structured Data
This type of data is organized in rows and columns, much like a spreadsheet or database table. Each column has a defined meaning, such as name, age, or city, and each row represents a single record. Because it follows a fixed format, structured data is easy to store, search, and analyze using SQL or spreadsheet tools. Examples include sales records, student lists, and financial transactions.
Unstructured Data
This type of data has no predefined structure and includes text, images, audio, and video. It is more complex to process but holds valuable insights. Techniques such as Natural Language Processing (NLP) and Deep Learning are used to extract meaning from it. Examples include emails, tweets, documents, photos, and videos.
Semi-Structured Data
This data has some organization but does not follow a strict format. It sits between structured and unstructured data. JSON and XML files are good examples. They contain tags and key-value pairs but are flexible in structure. Semi-structured data is common in APIs, emails, and log files where flexibility is preferred over consistency.
2.2 By Measurement Nature
Data can also be classified by how it is measured. Some data represents quantities that can be calculated, while others describe categories, labels, or time-based patterns. Understanding these measurement types helps you choose the right statistical methods, visualizations, and machine learning models for your analysis.
Numerical Data
This type of data represents measurable quantities that can be expressed as numbers. It allows mathematical and statistical operations such as addition, averaging, or correlation analysis. Numerical data helps in understanding patterns, making predictions, and measuring performance.
- Continuous Data – Refers to values that can take any number within a specific range. It is measured, not counted, and can include fractions or decimals. Continuous data provides more precision and is common in physical measurements, such as temperature, height, weight, or time duration.
- Discrete Data – Refers to countable values that usually appear as whole numbers. It cannot take fractional values and is often used when tracking counts or occurrences, such as the number of customers, sales transactions, website clicks, or product units sold. Numerical data is widely used in forecasting, regression models, performance analysis, and trend evaluation.
Numerical data is widely used in areas such as forecasting, regression models, performance analysis, and trend evaluation.
Categorical Data
This type of data represents characteristics, names, or categories that describe qualitative information rather than quantities. It cannot be measured but can be grouped, classified, or compared. Categorical data helps identify relationships between different groups in surveys, customer analysis, and classification models.
- Nominal Data – Refers to labels or categories without any natural order. Each category is unique but cannot be ranked or compared quantitatively. Examples include gender, color, city, or department name.
- Ordinal Data – Refers to categories that have a clear, logical order or ranking, though the distance between the categories is not defined. Examples include satisfaction levels such as low, medium, and high; education levels such as primary, secondary, and higher; or product ratings from 1 to 5 stars. Categorical data is common in business intelligence, marketing analysis, and machine learning classification tasks.
Categorical data is common in business intelligence, marketing analysis, and machine learning classification tasks.
2.3 By Time Orientation
Data can also be classified based on how it relates to time. This helps determine whether we are looking at a single moment or observing how something changes over days, months, or years.
Cross-Sectional Data
Cross-sectional data is collected at one specific point in time. It provides a snapshot of many individuals, items, or events at a single moment. This type of data is useful for comparing groups or understanding current conditions without considering past trends.
For example, a customer satisfaction survey collected today or a record of employees with their current salaries both represent cross-sectional data.
Time-Series Data
Time-series data is collected repeatedly at regular intervals, such as every hour, day, or month. It shows how a variable changes over time and is ideal for identifying trends, seasonal patterns, and forecasting future outcomes.
For example, daily stock prices, monthly revenue figures, or hourly temperature readings are all types of time-series data.
2.4 By Source
Data can also be classified based on who collects it and how it is obtained. Traditionally, this includes two main types: primary and secondary data. Understanding the difference helps you judge how reliable, relevant, and timely the data is for your AI or machine learning project.
Primary Data
Primary data is collected directly from the original source for a specific purpose. It is fresh, accurate, and aligned with the exact goal you want to achieve. This makes it highly reliable, but gathering it often requires more time, effort, and cost.
Primary data usually comes from activities such as surveys, interviews, experiments, observations, or real-time sensor readings. Because you control how and why it is collected, primary data often provides the highest level of relevance and quality.
For example, collecting customer feedback through your own survey or logging temperature readings from your IoT sensors.
Secondary Data
Secondary data is collected by someone else for a different purpose but reused for your analysis. It is easier, faster, and more affordable to obtain compared to primary data. However, it may not always perfectly match your current needs, and you may have less control over how it was collected.
Secondary data often comes from government publications, research papers, online databases, industry reports, or publicly available datasets. While it is convenient, it is important to check its accuracy, relevance, and licensing terms before using it.
For example, using census data, public health datasets, or market research reports available online.
2.5 Synthetic Data
Synthetic data is artificially generated using algorithms, simulations, or AI models to imitate real-world patterns. Instead of coming from surveys, users, or sensors, this type of data is created programmatically. It is helpful when real data is limited, sensitive, restricted by privacy laws, or too expensive to collect at scale.
Synthetic data offers several advantages. It supports safe experimentation without exposing personal or confidential information, and it allows you to create rare scenarios or balanced datasets that may not appear naturally. This makes it extremely useful for training machine learning models, especially in areas such as computer vision, fraud detection, healthcare, and autonomous systems.
For example, simulated customer transactions can be generated to test fraud models, artificial medical records can be created to protect patient privacy, or computer-generated images can be used to improve object detection systems.
3. Data Sources and Collection
Data comes from many different places. Some datasets are gathered manually through surveys, forms, or experiments, while others are collected automatically from sensors, apps, or enterprise systems. Web scraping and APIs are powerful tools for accessing online information, and public datasets from platforms like Kaggle or government repositories are widely used for research and practice.
However, not all data is equal. Before using any dataset, it is important to ensure it is relevant, ethical, and properly licensed. Using poor-quality or unauthorized data can lead to inaccurate results or legal issues. Ethical collection also means respecting privacy, collecting only what is necessary, and informing users about how their data will be used.
4. Data Terminology
Understanding data terminology is essential for anyone working in AI and machine learning. These concepts explain how data is collected, organized, processed, and managed throughout its lifecycle, helping you build a stronger foundation for analysis, modeling, and decision-making.
Basic Terms
Before exploring deeper concepts, it is important to understand the basic terms that describe how data is organized, stored, and interpreted. These terms help you understand what a dataset is made of, how individual entries are represented, and how information is documented and identified.
- Dataset – A collection of related data grouped together for analysis or model training. It is the main resource that algorithms use to learn patterns. For example, a dataset of customers may include their age, city, purchase history, and membership status.
- Record / Observation – A record is a single row or entry in a dataset. Each record represents one instance, such as one customer, one product, or one transaction. Thinking of data in terms of individual records helps you understand how each example contributes to the bigger picture.
- Feature / Attribute / Variable – A feature is a measurable property that describes each record. Age, income, height, city, and number of purchases are all features. Features provide the details that models analyze to find relationships and make predictions.
- Target / Label – The target is the outcome or value you are trying to predict. It could be whether a customer will churn, the price of a house, or the risk score of a patient. Understanding the target helps define the goal of your analysis.
- Feature Space – The feature space is the combined set of all features in a dataset. When you plot or visualize features together, they form a multi-dimensional space where patterns, trends, and clusters can be detected.
- Metadata – Metadata is information about the data itself. It describes things like data type, source, units, format, and when it was collected. Good metadata helps you understand the meaning and reliability of each field before using it.
- Schema – A schema defines the structure of a dataset or database. It explains how data is arranged, what each column represents, what type of values it contains, and how different tables relate to each other. A schema acts as the blueprint for your data.
- Data Dictionary – A data dictionary is a document that explains each column in a dataset in simple terms. It covers the column’s purpose, meaning, format, and allowed values. It ensures that everyone interprets the data consistently.
- Instance ID / Primary Key – This is a unique identifier assigned to each record. It prevents duplicates and makes it easy to track or update specific entries. Examples include customer IDs, transaction IDs, or product codes.
- Population – The population represents the full group you want to study. For example, all customers in a city, all students in a school, or all sales transactions in a year. It defines the complete scope of your analysis.
- Sample – A sample is a smaller part of the population selected for analysis. It helps you draw conclusions quickly without processing the entire dataset. A well-chosen sample can accurately represent the full population.
Intermediate Terms
Once data is collected, it goes through several steps to make it usable for analysis and machine learning. These terms describe the processes involved in cleaning, preparing, and organizing data so it can produce meaningful results.
- Data Profiling – This is the process of examining a dataset to understand its structure and quality. It helps you see patterns, detect missing values, find errors, and get a general idea of what the data contains. Profiling is often the first step before any cleaning or modeling begins.
- Data Wrangling / Munging – Raw data is often messy, incomplete, or scattered across different formats. Wrangling means converting this messy data into a structured and usable form. It may involve correcting errors, merging tables, fixing formats, or removing irrelevant information so the data becomes ready for analysis.
- Data Preprocessing – This step prepares data so it can be used effectively by machine learning algorithms. It includes handling missing values, encoding text labels into numbers, scaling numerical features, and correcting inconsistent formats. Good preprocessing improves model accuracy and reliability.
- Data Transformation – Data often needs to be converted from one format to another so it becomes easier to analyze. Transformation may include changing units, creating new features, reshaping tables, or converting date formats. For example, turning dollar amounts into rupees or extracting the month from a date.
- Data Integration – Many organizations store data in different places. Integration means bringing data from multiple sources together into one unified dataset. This helps build a complete picture and reduces duplication or gaps in information.
- Data Sampling – Sometimes datasets are too large or too slow to work with all at once. Sampling means selecting a smaller portion of the data that still represents the whole. It is useful for quick tests, model training, or performing experiments without using full datasets.
- Data Annotation / Labeling – For supervised learning, data needs correct answers or labels. Annotation means tagging data with these correct outputs. For example, marking an image as a cat or dog, or labeling customer messages as positive or negative. Labeled data teaches models what patterns to look for.
- Data Imputation – Real-world datasets often have missing values. Imputation is the process of filling these gaps using methods like averages, medians, or predictive models. This helps maintain consistency and ensures the dataset stays complete without removing too many records.
- Data Normalization / Standardization – Different features may have different scales, such as age in years and salary in rupees. Normalization and standardization adjust these values to a similar range so no feature dominates the others. This makes model training more stable and balanced.
Advanced Terms
As data grows in size and complexity, organizations use advanced systems and techniques to manage, monitor, and protect it. These terms focus on large-scale data handling, automation, and maintaining reliable machine learning performance.
- Data Pipeline – A data pipeline is an automated sequence of steps that moves data from its source to its final destination. It can include collecting, cleaning, transforming, and loading data so it is always ready for use without manual work.
- ETL (Extract, Transform, Load) – ETL is a traditional process where data is first extracted from sources, cleaned and transformed, and then loaded into storage systems such as databases or data warehouses. It ensures that only processed, high-quality data is stored.
- ELT (Extract, Load, Transform) – ELT reverses the order by loading raw data first and transforming it afterward, usually inside cloud data platforms. This approach is faster and more flexible for large datasets.
- Data Warehouse – A data warehouse is a centralized storage system that holds clean, structured, and historical data. It is optimized for reporting, dashboards, and business analysis.
- Data Lake – A data lake is a large storage repository that keeps raw data in all formats, including text, images, logs, and videos. It is widely used in AI, machine learning, and big-data projects that require unprocessed information.
- Data Governance – Data governance refers to the policies, rules, and responsibilities that ensure data is accurate, secure, and used properly. It defines who can access data, how it should be handled, and how compliance is maintained.
- Data Lineage – Data lineage tracks the journey of data, showing where it originated, how it changed, and where it was used. This helps teams understand errors, increase transparency, and maintain trust in their data.
- Data Catalog – A data catalog is a searchable inventory of datasets. It helps teams quickly find, understand, and use the right data by providing descriptions, usage details, and metadata.
- Data Versioning – Data versioning keeps records of how a dataset changes over time. It ensures that experiments are reproducible, models are consistent, and older data can be restored if needed.
- Data Drift – Data drift occurs when the input data slowly changes over time, causing models to become less accurate. Monitoring drift helps identify when a model needs updates.
- Concept Drift – Concept drift happens when the relationship between input features and the target changes. Even if the data looks similar, the meaning behind it shifts, and models must be retrained.
- Data Leakage – Data leakage happens when information from outside the training dataset unintentionally influences the model. This leads to unrealistically high accuracy during training but poor performance in real-world use.
- Data Privacy – Data privacy focuses on protecting personal or sensitive information from misuse or unauthorized access. It ensures individuals’ rights and confidentiality are respected.
- Anonymization – Anonymization removes or masks identifying details in a dataset so no individual can be traced, even when the data is shared or analyzed.
- Data Compliance – Data compliance means following legal and regulatory standards, such as GDPR, HIPAA, or CCPA, when collecting and handling data. It ensures that organizations operate within the law.
- Bias and Fairness – Bias and fairness ensure that datasets and models do not favor or discriminate against any group. Addressing bias creates more ethical, reliable, and inclusive AI systems.
5. Data Quality Dimensions
The quality of your data determines the strength of your insights and the performance of your models. Even the most advanced algorithms cannot fix low-quality data. These eight dimensions help you evaluate whether your data is accurate, consistent, complete, and reliable enough to support AI and analytics work.
- Accuracy – Accuracy ensures that data correctly represents real-world facts. When data is inaccurate, your conclusions will be misleading. For example, if a customer’s recorded age is 58 instead of 28, predictions based on that record will be wrong. Accurate data comes from verified sources, uses reliable measurements, and directly reflects reality, which makes your models more trustworthy.
- Completeness – Completeness measures whether all necessary information is available. Missing values or incomplete records weaken the analysis and reduce model accuracy. For example, if many customer entries are missing income or location data, segmentation results become unreliable. Complete data ensures that every essential attribute is filled and the dataset provides a full picture for decision-making.
- Consistency – Consistency ensures data follows the same standards and format across systems and time. Inconsistent data such as “USA” in one database and “United States” in another causes confusion and integration issues. Consistent data uses standardized units, codes, and definitions so that different systems can communicate seamlessly and produce aligned results.
- Timeliness – Timeliness checks whether your data is current and relevant. Outdated data can lead to poor decisions, like using last year’s customer behavior to predict this year’s trends. Timely data is collected, updated, and refreshed regularly to reflect the present context. In AI applications, especially those involving user activity or market trends, real-time or near real-time data improves model responsiveness and accuracy.
- Validity – Validity determines whether data follows defined rules, constraints, or formats. For instance, an “Age” column should not contain negative numbers or text. Invalid entries introduce noise and errors into analysis pipelines. By enforcing validation rules such as data type checks or logical constraints, you ensure that only meaningful and acceptable values enter the system.
- Relevance – Relevance measures whether the data you collect is actually useful for the specific goal or analysis. Irrelevant data adds noise, slows down processing, and distracts models from meaningful signals. For example, collecting shoe size data for a credit risk model provides no value. Relevant data directly supports the business question or model objective you are addressing.
- Uniqueness – Uniqueness ensures that every record appears only once in the dataset. Duplicate entries such as the same customer entered twice under slightly different names can distort analysis, inflate counts, or bias models. Regular deduplication and the use of unique identifiers like customer IDs keep your dataset clean and reliable.
- Integrity – Integrity ensures that relationships between datasets remain accurate and logically connected. For example, every sales record should point to a valid customer record, and every transaction should belong to a real account. When these links break, analysis becomes unreliable. Maintaining referential integrity guarantees that your data ecosystem functions as a coherent, dependable system.
Data quality is not just about correctness; it is about trust. Accurate and complete data reflects truth, consistency and integrity ensure harmony, while timeliness and relevance make your data valuable for real-world decisions. High-quality data turns information into intelligence.
6. Data Governance, Security, and Ethics
Data governance, security, and ethics ensure that data is collected, managed, and used responsibly. Together, they protect privacy, prevent misuse, and promote fairness in AI and analytics.
Ethical Data Use
Ethical data practices begin with one question: Should this data be collected and used? Collect only what is necessary, explain how it will be used, and always seek informed consent from users. Transparency and accountability at every step build trust and prevent harm. Responsible data use goes beyond compliance; it reflects the values of fairness and respect for privacy.
Data Privacy and Fairness
Protecting personal information is a top priority in every data-driven project. Techniques like anonymization, aggregation, and differential privacy help reduce the risk of exposing individual identities. Equally important is maintaining fairness. If historical data contains bias, AI systems can unintentionally amplify it. Ensuring diverse representation and balanced training datasets helps create models that serve everyone equally.
Data Governance and Regulation
Data governance defines who owns the data, who can access it, and how it is maintained. It establishes clear responsibilities across the organization. Regulations such as the GDPR in Europe, HIPAA in the United States, and CCPA in California set global standards for data protection and privacy. A strong governance framework ensures compliance, reduces risk, and builds public trust in AI technologies.
7. Real-World Data Challenges
In real-world projects, data is rarely perfect. It often comes from multiple systems, arrives in inconsistent formats, or changes faster than teams can adapt. Understanding these challenges helps organizations plan better and maintain reliable machine learning pipelines.
- Data Silos – Many organizations store information in separate systems or departments, making it difficult to share or combine data. These silos limit visibility, prevent collaboration, and create duplicate work. Breaking them requires strong data integration practices and unified platforms.
- Incomplete or Inconsistent Data – Missing values, conflicting formats, and outdated records are common issues. Incomplete or inconsistent data can slow down projects and reduce model accuracy. Establishing clear data entry standards and automated validation checks helps minimize such problems.
- Data Drift – User behavior and market conditions change constantly, which can alter data patterns over time. This phenomenon, called data drift, causes models to lose accuracy. Regular monitoring and model retraining help maintain reliability as real-world conditions evolve.
- Privacy and Regulation – Strict privacy laws such as GDPR and HIPAA restrict how data can be collected and used. Teams must balance innovation with compliance by using techniques like anonymization, differential privacy, or synthetic data generation to protect users while keeping data useful.
- Miscommunication and Misalignment – Human factors can be just as challenging as technical ones. When business leaders and data teams do not share a clear understanding of goals, projects can fail to deliver value. Regular communication, clear documentation, and shared definitions ensure everyone works toward the same outcome.
- Skill Gaps and Resource Limits – Some organizations lack skilled data professionals or the right infrastructure to manage large-scale data projects. Investing in training, automation tools, and cloud platforms can help close these gaps and improve efficiency.
- Balancing Quality and Speed – In fast-paced environments, teams often prioritize quick results over data quality. However, rushing through data preparation can lead to long-term problems. Striking the right balance between speed and accuracy ensures both productivity and reliability.
8. How to Tackle Data Challenges
Solving data challenges requires a mix of technical tools and good organizational practices. The first step is building a unified data environment so information does not remain trapped in separate systems. Using data warehouses, shared dashboards, and integration tools helps break down silos and keeps teams aligned.
Improving data quality starts with clear standards for data entry, automated validation rules, and regular data cleaning routines. Techniques such as imputation for missing values, de-duplication, and format standardization ensure data stays reliable. For issues like data drift, continuous monitoring and scheduled model retraining help models stay accurate as user behavior changes.
To balance privacy with usability, teams can apply anonymization, differential privacy, or synthetic data generation when dealing with sensitive information. Clear communication across teams, well-defined responsibilities, and documentation help prevent misalignment and confusion. Finally, investing in training, automation, and scalable cloud tools helps organizations manage growing data needs more efficiently.
9. Conclusion: Master Data Before Models
Understanding the Fundamentals of Data is essential for building reliable and responsible AI systems. When you know how data is structured, where it comes from, how it is cleaned, and how its quality affects model performance, you gain real control over your machine learning results. Ethical collection, strong governance, and respect for privacy ensure that your work stays trustworthy and aligned with real-world needs.
A true AI professional goes beyond analysis. They study data deeply, question its origins, respect its limitations, and continuously improve its quality. When you follow the Fundamentals of Data in every project, you do more than build intelligent systems. You create solutions that make a meaningful and positive impact on the world.
10. References
- Prashanth Southekal. Data Quality: Empowering Businesses with Analytics and AI. G&D Media.
- Aurélien Géron. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media.
- Aurélien Géron. Hands-On Machine Learning with Scikit-Learn and PyTorch: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media.
- European Union. General Data Protection Regulation (GDPR).
- U.S. Department of Health & Human Services. Health Insurance Portability and Accountability Act (HIPAA).
- IBM. What Is Data Governance?