
Transformers run the AI tools we use every day, but the technology behind them is often hidden. Most users never get to see how attention works, why some models generate better text, or how alignment and RAG keep outputs accurate. Understanding these foundations makes today’s AI far less mysterious.
Transformers in Action (affiliate link) by Nicole Königstein, Co-Founder and Chief AI Officer at the fintech company Quantmate, is published by Manning Publications and explains these concepts in a clear and practical way. Nicole shows how transformers began, how the attention mechanism changed the field, and how today’s models are trained, optimized, aligned, and deployed in real applications.
In this review, I have summarized ten key insights from the book. These insights will help you understand how modern transformer models work and how you can apply them in real projects.
10 Key Insights from Transformers in Action
1. Transformers solved the limits of older neural networks
For years, RNNs and LSTMs carried NLP on their shoulders, but they came with real limits. They forgot information, broke down on long sentences, trained slowly, and struggled with complex reasoning. Nicole explains how these models tried to understand sequences step by step and ended up losing context exactly when it mattered the most. Translation systems before transformers were perfect examples of this struggle. They worked, but only up to a point.
If you want a simple foundation in NLP, check out Mastering NLP: A Journey Through Sentiment Analysis.
Transformers changed the entire field by taking a different path. Instead of moving one token at a time, they look at everything together. Attention lets the model highlight what really matters in a sentence, while multihead attention catches multiple relationships at once. Positional encoding gives order without forcing slow, stepwise processing. With these ideas, transformers became faster, more stable, and far more accurate. This breakthrough became the blueprint for modern large language models.
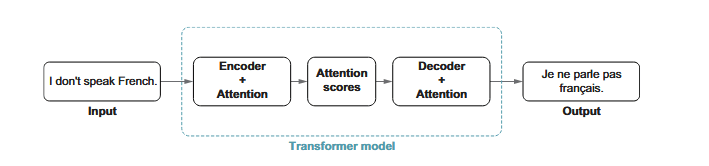
Used with permission.
2. Attention is the core idea that gives transformers true understanding
Nicole explains attention as the idea that changed everything for NLP. Instead of walking through a sentence one token at a time, attention lets every word look at every other word at once. This removes the fragile memory bottleneck of RNNs and allows the model to highlight the most important parts of a sequence instantly.
She also shows how multihead attention gives the model several perspectives at the same time. One head may track grammar, another sentiment, another context. Positional encoding adds order so the model does not lose track of how the sequence flows. These components together form the core of why transformers understand long sequences so well and why they outperformed older architectures almost overnight.
3. Decoder only and encoder only architectures power different use cases
Nicole breaks down transformer families into two clear groups that behave very differently. Decoder only models, such as GPT, generate text one token at a time and are built for writing, reasoning, summarizing, and open ended dialogue. Encoder only models, like BERT, read the entire sequence at once using bidirectional attention. This makes them excellent for classification, retrieval, search, and understanding tasks where accuracy matters more than generation.
She also explains how embedding models and Mixture of Experts expand the transformer toolkit. Embedding models turn text into dense vectors that power search engines and RAG pipelines. MoE models let large systems scale by activating only a few expert networks per input, giving them high capacity without high inference cost.
By grouping these architectures side by side, Nicole helps readers understand why no single transformer does everything. Choosing the right family makes models faster, cheaper, and more accurate for the task you want to solve.
4. Modern text generation depends on smart decoding and prompting
Nicole makes it clear that great text generation is not just about having a strong model. It is about how you guide the model. She explains that decoding controls the shape and creativity of the output. Greedy search gives the safest next token, beam search explores multiple candidate paths, and sampling methods like top-k, nucleus, and temperature add controlled randomness. With the right mix, you can shift a model from factual and focused to creative and expressive.
Prompting forms the second half of this system. Nicole walks through zero-shot and few-shot prompting for basic tasks, then moves into more advanced methods like chain-of-thought and tree-of-thought, which help the model reason step by step. Techniques such as contrastive CoT, CoVe, and ToT reduce errors, improve structure, and give more reliable answers.
Together, decoding and prompting shape the model’s behavior more than most users realize. This insight shows how anyone can get better, safer, and more consistent results simply by choosing the right decoding strategy and crafting the right prompt.
5. Alignment and RAG make LLMs useful, safe, and accurate
The book shows that alignment is what turns raw model power into useful behavior. Techniques like RLHF, DPO, and GRPO help models learn human preferences, avoid harmful outputs, and respond more reliably. MixEval supports this by evaluating models on realistic tasks, making alignment easier to measure and improve.
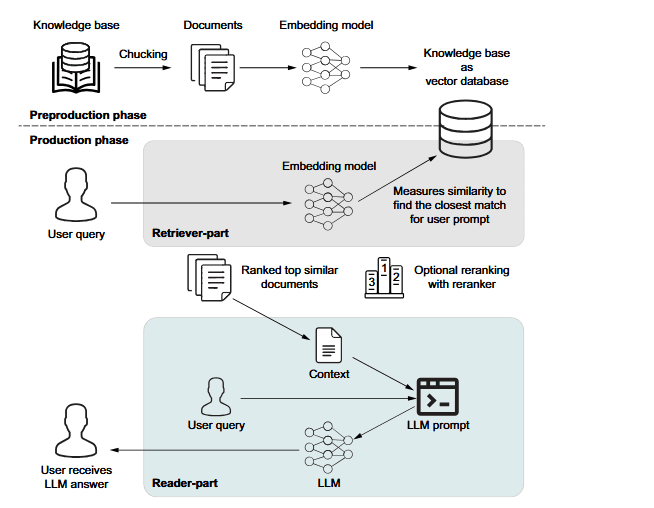
Used with permission.
It also explains how retrieval augmented generation keeps answers factual and grounded. RAG brings in external knowledge at the right moment, reducing hallucinations and improving accuracy. Newer forms like agentic, corrective, and fusion RAG show how retrieval can evolve into smarter, multi step reasoning. Together, alignment and retrieval make modern LLMs safer, sharper, and ready for real world use.
6. Multimodal models connect text, images, audio, and video
Multimodal transformers extend language models beyond text by converting images, audio, and video into numerical embeddings. Images are broken into patches, audio becomes spectrogram based features, and video is represented through spatiotemporal cubes. This lets the model handle different kinds of data in a unified way.
Once everything is mapped into the same space, the model can combine signals across modalities. It can describe images, analyze documents, interpret charts, extract details from video, or answer questions that require multiple types of input.
Multimodal RAG strengthens this further by retrieving information from PDFs, tables, screenshots, diagrams, and mixed documents. This produces richer, more grounded outputs and makes multimodal transformers especially useful for assistants, analytics tools, and enterprise applications.
7. Small and efficient models are becoming powerful specialists
The author highlights a major shift in the AI landscape: small language models are no longer backups or lightweight alternatives. They are becoming specialists. These compact models run faster, cost less, and can be fine tuned for very focused tasks such as classification, translation, sentiment detection, and guardrail filtering. Examples like adapting Gemma 270M for empathy and English–Spanish translation show how much capability can be packed into a small footprint.
The book also shows how these small models fit into larger ecosystems. They can act as agents, safety layers, routing components, or optimizers within bigger pipelines. Instead of forcing one giant model to do everything, small models provide targeted intelligence exactly where it is needed, creating systems that are cheaper, more efficient, and often more accurate for specific tasks.
8. Training and fine tuning large language models requires smart techniques
Training large models demands more than data and compute. It requires well-chosen hyperparameters, stable optimization, and disciplined experiment tracking. Poor settings can slow learning or destabilize gradients, which is why structured tools for tuning and monitoring are essential.
Nicole also highlights how techniques like LoRA, QLoRA, and other PEFT methods make fine tuning affordable by updating only a small portion of the model’s weights. Quantization reduces memory use even further while keeping performance strong. Together, these approaches show how teams can adapt large models efficiently without massive hardware.
9. Scaling transformers needs efficient optimization at the system level
Transformers in Action explains that making big models run smoothly needs smart engineering. Techniques like pruning and distillation make the model smaller and lighter. Sharding spreads the model across many GPUs so even very large models can fit in memory. Nicole also describes methods that make models respond faster, such as KV caching, paged attention, FlashAttention, and efficient GPU scheduling.
If you’d like to explore another transformer book, here’s my review of Transformers for NLP and Computer Vision.
The book also shows how models can handle longer inputs. Rotary embeddings and newer methods like YaRN and iRoPE help extend the context window without breaking performance. These ideas make transformers faster, cheaper, and easier to use in real-world systems.
10. Responsible AI ensures large models remain safe, fair, and trustworthy
Responsible AI begins with understanding how training data can introduce bias into a model’s predictions. These hidden patterns may lead to unfair or unintended behavior, so developers must learn how to identify and correct them early. Nicole explains why examining data sources and model outputs is essential before any system is deployed.
Transparency plays an equally important role. Tools such as Captum and LIME help reveal how a model makes decisions, making it easier to analyze its behavior and improve reliability. By showing how these tools work in practice, Nicole makes the idea of explainability much more accessible.
Safety measures complete the foundation. Techniques like jailbreak prevention, prompt and response scanning, and continuous monitoring protect models from misuse and harmful prompts. These safeguards ensure that large language models operate responsibly in real environments, a core message reinforced throughout Transformers in Action.
Who This Book Is For
- Readers who want a clear and practical introduction to transformer models
- Data scientists and machine learning engineers who are ready to work with modern language and multimodal systems
- Learners who want to build a strong foundation before moving into advanced architectures
- Professionals who want to understand how transformers power real applications
- Anyone interested in applying transformer based models with confidence
Final Thoughts
Transformers in Action stands out because it does more than explain how transformers work. It shows how to apply them with confidence. Nicole Königstein presents each concept with clarity and supports it with well-structured, easy-to-understand code examples that make even advanced ideas feel accessible. The writing is practical, clear, and designed to help readers build real skills, not just collect information.
Whether you are working with LLMs, exploring multimodal systems, or optimizing models for real applications, the insights in this book give you a solid direction to move forward. If you want to deepen your understanding of modern AI architecture and learn methods used by leading teams today, Transformers in Action is a valuable and practical guide worth reading.
Buy the Book
If you want a clear and practical guide to transformer models, Transformers in Action by Nicole Königstein is available through the following links:
- Buy on Amazon (affiliate link)
- Buy on Manning (affiliate link):
This book is a reliable learning companion if you want to understand how modern transformer models work and how they are applied in real projects.
Disclosure: This article about Transformers in Action contains affiliate links. If you buy through these links, we may earn a small commission at no extra cost to you. It helps us keep creating free content on Noro Insight.


